
反向传播
反向传播是用来计算给定函数\(f(x)\)关于\(x\)的梯度\(\bigtriangledown f(x)\),根据梯度可以更快地进行参数更新。
简单表达式
函数变量在某个点周围的极小区域内变化,导数和偏导数就是沿着某个方向的变化率,而梯度则是偏导数的向量:
\[\frac{df(x)}{dx}=lim_{h \to 0}\frac{f(x+h)-f(x)}{h}\] \[\bigtriangledown f(x, y)=[\frac{\partial f}{x}, \frac{\partial f}{y}]\]链式法则
链式法则就是我们高数里学过的,复合函数求导时,导数等于各个复合函数梯度表达式(导数)的乘积。在实际代码实现时,只是单纯将两个梯度数值相乘:
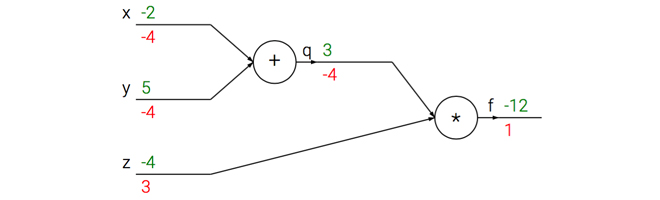
# 设置输入值
x = -2; y = 5; z = -4
# 进行前向传播
q = x + y # q becomes 3
f = q * z # f becomes -12
# 进行反向传播:
# 首先回传到 f = q * z
dfdz = q # df/dz = q, 所以关于z的梯度是3
dfdq = z # df/dq = z, 所以关于q的梯度是-4
# 现在回传到q = x + y
dfdx = 1.0 * dfdq # dq/dx = 1. 这里的乘法是因为链式法则
dfdy = 1.0 * dfdq # dq/dy = 1图中展示了计算的过程,前向传播将输入值用于计算输出,反向传播从尾部开始,利用链式法则递归计算梯度。
反向传播的意义
反向传播可以看做门单元之间通过梯度信号进行通信,让它们的输入沿着梯度方向变化,局部计算后可以提升整个网络的输出值。实际上,无论是乘法、加法还是MAX都可以看做是门。初此之外还有以下四种门:
\[f(x)=\frac{1}{x} \to \frac{df}{dx}=-\frac{1}{x^2}\] \[f_c(x)=c+x \to \frac{df}{dx}=1\] \[f(x)=e^x \to \frac{df}{dx}=e^x\] \[f_a(x)=ax \to \frac{df}{dx}=a\]其中包括将输入值平移和实数倍放大的函数。
- Sigmoid例子
一个函数可以看成多个门的结合,下面的表达式描述了一个含输入\(x\)和权重\(W\)的二维神经元,该神经元使用了sigmoid激活函数。这个函数可以如下计算:
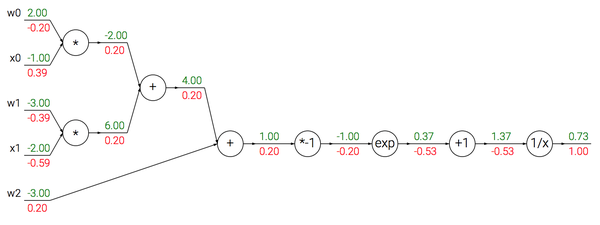 对于sigmoid函数,其求导使可以进行简化的,因为我们发现:
\(\sigma(x)=\frac{1}{1+e^{-x}}\)
\(\frac{d\sigma(x)}{dx}=(1-\sigma(x))\sigma(x)\)
而在具体实现中,可以使用分段的反向传播,可以让局部梯度计算简洁,代码量小,效率高。
对于sigmoid函数,其求导使可以进行简化的,因为我们发现:
\(\sigma(x)=\frac{1}{1+e^{-x}}\)
\(\frac{d\sigma(x)}{dx}=(1-\sigma(x))\sigma(x)\)
而在具体实现中,可以使用分段的反向传播,可以让局部梯度计算简洁,代码量小,效率高。
w = [2,-3,-3] # 假设一些随机数据和权重
x = [-1, -2]
# 前向传播
dot = w[0]*x[0] + w[1]*x[1] + w[2]
f = 1.0 / (1 + math.exp(-dot)) # sigmoid函数
# 对神经元反向传播
ddot = (1 - f) * f # 点积变量的梯度, 使用sigmoid函数求导
dx = [w[0] * ddot, w[1] * ddot] # 回传到x
dw = [x[0] * ddot, x[1] * ddot, 1.0 * ddot] # 回传到w- 分段计算 输入的函数如下: \(f(x,y)=\frac{x+\sigma(y)}{\sigma(x)+(x+y)^2}\) 这个函数如果进行微分运算,将会得到巨大复杂的展开式。其实我们根本不需要明确的函数来计算梯度,只需要通过反向传播就好了。首先构建前向传播的代码:
x = 3 # 例子数值
y = -4
# 前向传播
sigy = 1.0 / (1 + math.exp(-y)) # 分子中的sigmoi #(1)
num = x + sigy # 分子 #(2)
sigx = 1.0 / (1 + math.exp(-x)) # 分母中的sigmoid #(3)
xpy = x + y #(4)
xpysqr = xpy**2 #(5)
den = sigx + xpysqr # 分母 #(6)
invden = 1.0 / den #(7)
f = num * invden # 搞定! #(8)然后这些中间变量都是比较简单的表达式,它们计算梯度的方法都很简单。所以我们只需要将这些变量的值进行回传就可以计算对应的梯度了:
# 回传 f = num * invden
dnum = invden # 分子的梯度 #(8)
dinvden = num #(8)
# 回传 invden = 1.0 / den
dden = (-1.0 / (den**2)) * dinvden #(7)
# 回传 den = sigx + xpysqr
dsigx = (1) * dden #(6)
dxpysqr = (1) * dden #(6)
# 回传 xpysqr = xpy**2
dxpy = (2 * xpy) * dxpysqr #(5)
# 回传 xpy = x + y
dx = (1) * dxpy #(4)
dy = (1) * dxpy #(4)
# 回传 sigx = 1.0 / (1 + math.exp(-x))
dx += ((1 - sigx) * sigx) * dsigx # Notice += !! See notes below #(3)
# 回传 num = x + sigy
dx += (1) * dnum #(2)
dsigy = (1) * dnum #(2)
# 回传 sigy = 1.0 / (1 + math.exp(-y))
dy += ((1 - sigy) * sigy) * dsigy #(1)
# 完成! 嗷~~中间有大量的中间变量需要缓存,在不同分支的梯度计算后,如果同一变量在前向传播中出现多次,就要通过微积分中的多元链式法则进行累加。
回传流中的模式
观察一个包括加法乘法流的例子:
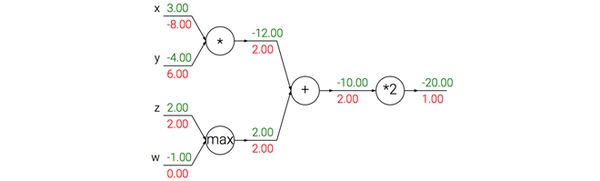
可以看出,每种门单元有着不同的回传机制:
- 加法门:把输出的梯度相等地分发给它所有的输入,这一行为与输入值在前向传播时的值无关。这是因为加法操作的局部梯度都是简单的+1,所以所有输入的梯度实际上就等于输出的梯度,因为乘以1.0保持不变。
- max门:对梯度做路由。取最大值门将梯度转给其中一个输入,这个输入是在前向传播中值最大的那个输入。这是因为在取最大值门中,最高值的局部梯度是1.0,其余的是0。(选择器)
- 乘法门:它的局部梯度就是输入值,但是是相互交换之后的,然后根据链式法则乘以输出值的梯度。但是如果一个输入非常大,一个非常小,那么交换后获得的梯度将会跟输入数据的大小密切相关。
矩阵操作
当真正进行计算时,大多是矩阵和向量操作。矩阵相乘时有很多好的操作习惯,比如矩阵转置,比如维度分析:
# 前向传播
W = np.random.randn(5, 10)
X = np.random.randn(10, 3)
D = W.dot(X)
# 假设我们得到了D的梯度
dD = np.random.randn(*D.shape) # 和D一样的尺寸
dW = dD.dot(X.T) #.T就是对矩阵进行转置
dX = W.T.dot(dD)通过反向传播,程序可以通过简单地编写实现高效的参数计算。下节课我将会学习神经网络的基本概念,而其其训练的数学理论基本就来源于最优化与反向传播了。